

Abstract
Cinematographers adeptly capture the essence of the world, crafting compelling visual narratives through intricate camera movements. Witnessing the strides made by large language models in perceiving and interacting with the 3D world, this study explores their capability to control cameras with human language guidance. We introduce ChatCam, a system that navigates camera movements through conversations with users, mimicking a professional cinematographer's workflow. To achieve this, we propose CineGPT, a GPT-based autoregressive model for text-conditioned camera trajectory generation. We also develop an Anchor Determinator to ensure precise camera trajectory placement. ChatCam understands user requests and employs our proposed tools to generate trajectories, which can be used to render high-quality video footage on radiance field representations. Our experiments, including comparisons to state-of-the-art approaches and user studies, demonstrate our approach's ability to interpret and execute complex instructions for camera operation, showing promising applications in real-world production settings.
Method

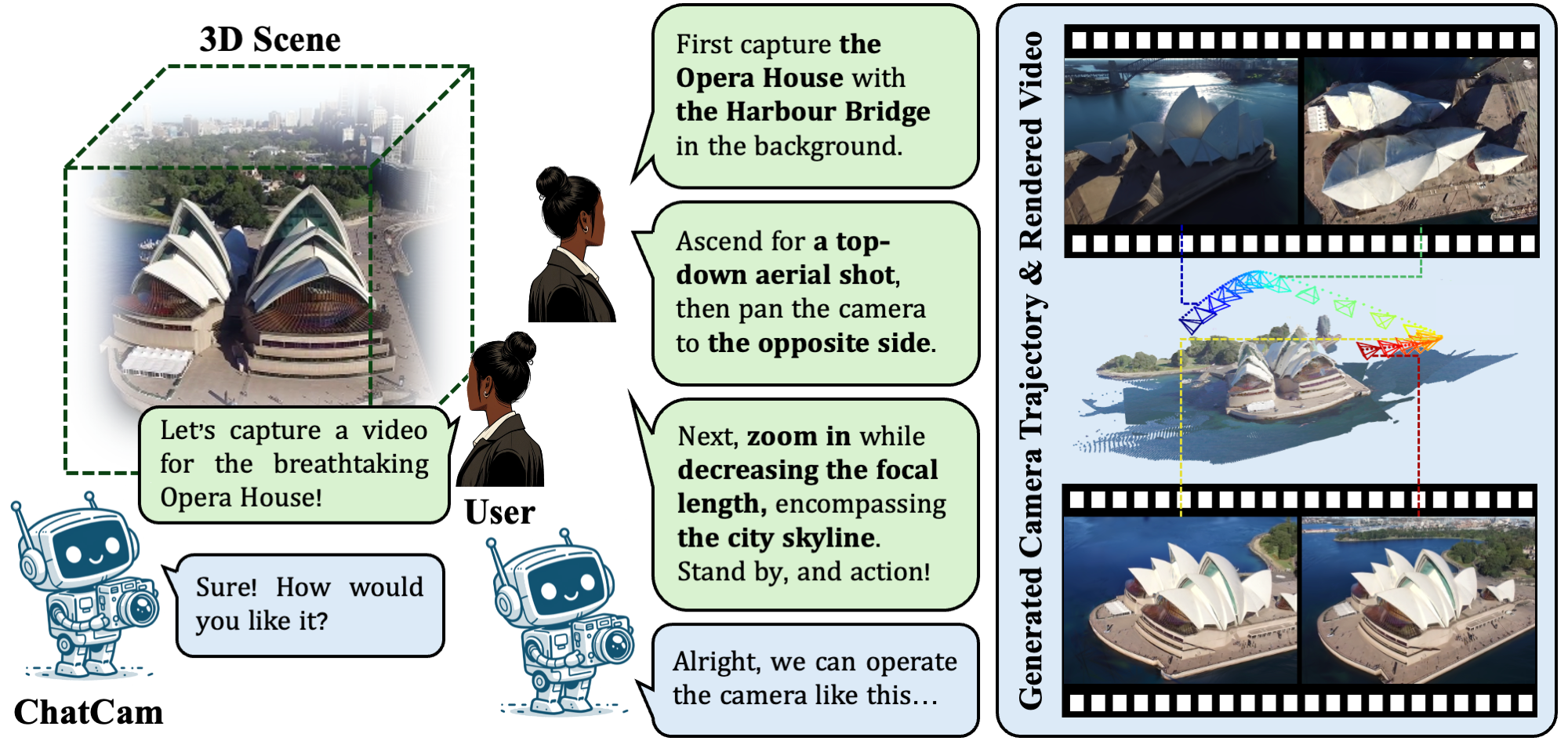
Given a camera operation instruction, ChatCam reasons the user's request and devises a plan to generate a trajectory using our proposed CineGPT and Anchor Determinator. The agent then utilizes the outputs from these tools to compose the complete trajectory and render a video.
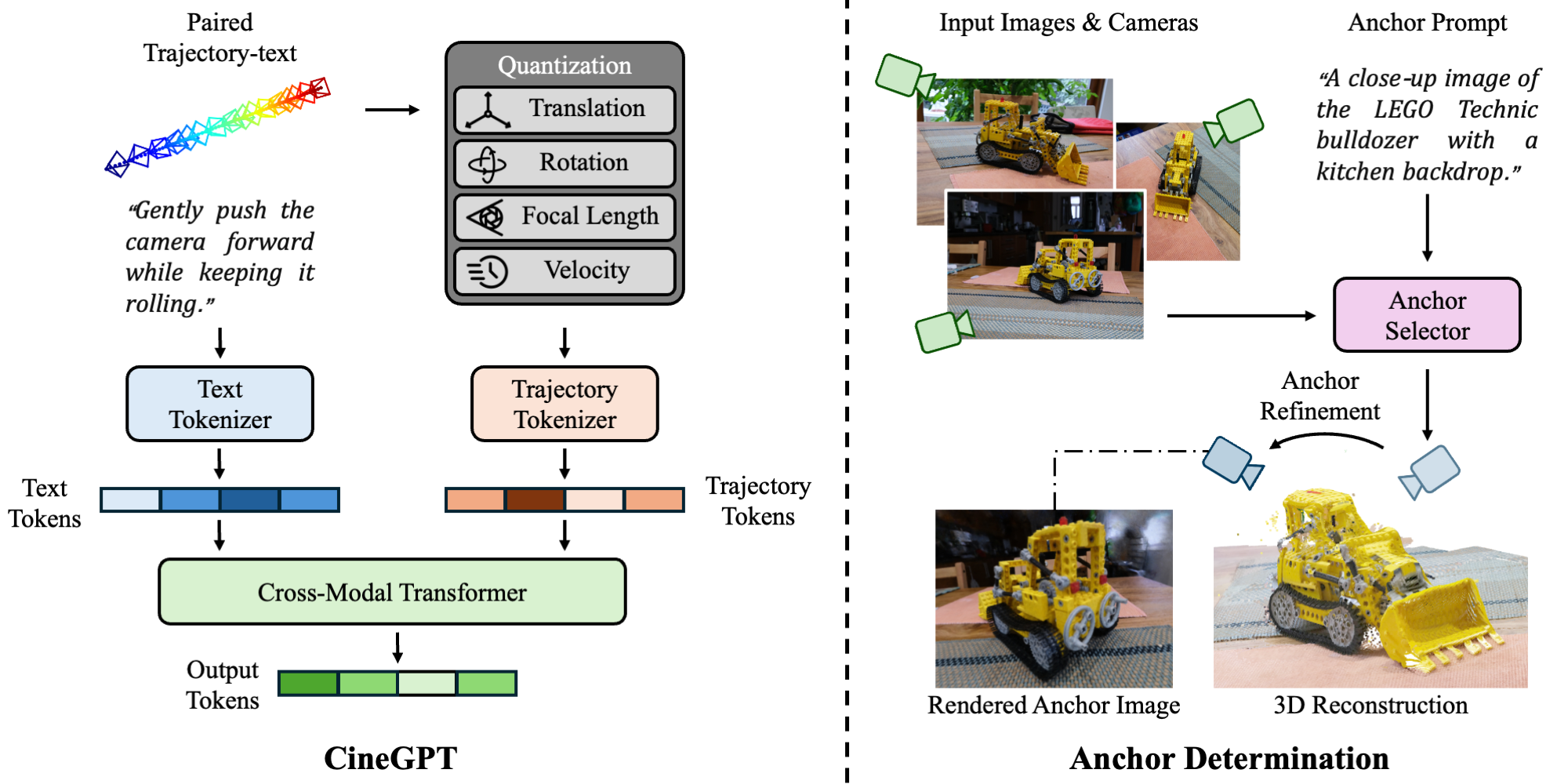
(a) CineGPT. We quantize camera trajectories to sequences of tokens and adopt a GPT-based architecture to generate the tokens autoregressively. Learning trajectory and language jointly, CineGPT is capable of text-conditioned trajectory generation. (b) Anchor Determination. Given a prompt describing the image rendered from an anchor point, the anchor selector chooses the best matching input image. An anchor refinement procedure further fine-tunes the anchor position.
Results

Citation
Acknowledgements
The website template was borrowed from Michaël Gharbi.