

Abstract
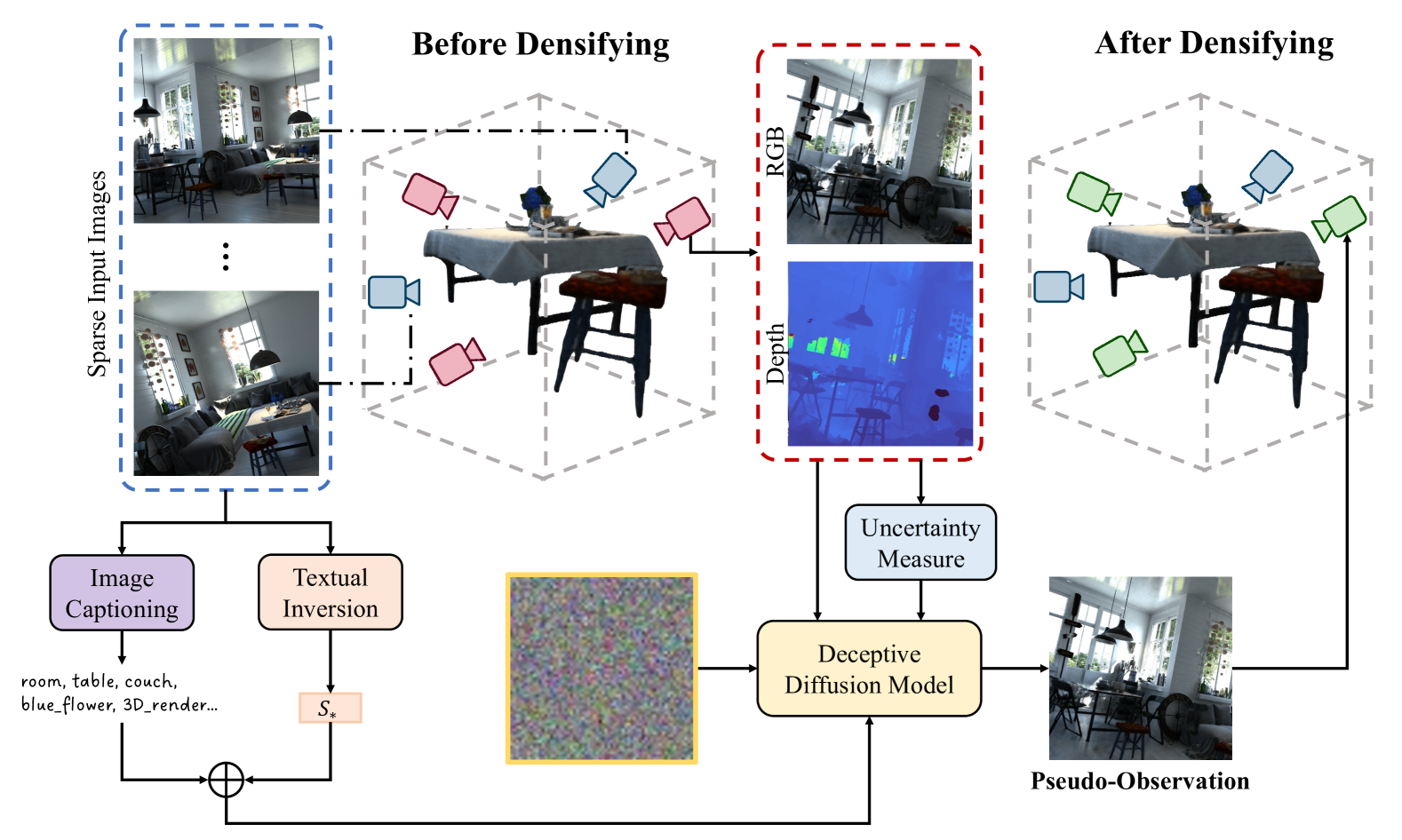
Novel view synthesis via Neural Radiance Fields (NeRFs) or 3D Gaussian Splatting (3DGS) typically necessitates dense observations with hundreds of input images to circumvent artifacts. We introduce Deceptive-NeRF/3DGS to enhance sparse-view reconstruction with only a limited set of input images, by leveraging a diffusion model pre-trained from multiview datasets. Different from using diffusion priors to regularize representation optimization, our method directly uses diffusion-generated images to train NeRF/3DGS as if they were real input views. Specifically, we propose a deceptive diffusion model turning noisy images rendered from few-view reconstructions into highquality photorealistic pseudo-observations. To resolve consistency among pseudo-observations and real input views, we develop an uncertainty measure to guide the diffusion model's generation. Our system progressively incorporates diffusion-generated pseudo-observations into the training image sets, ultimately densifying the sparse input observations by 5 to 10 times. Extensive experiments across diverse and challenging datasets validate that our approach outperforms existing state-of-the-art methods and is capable of synthesizing novel views with super-resolution in the few-view setting.
Citation
Acknowledgements
The website template was borrowed from Michaël Gharbi.